Source : Board Infinity
Memahami Underfitting dan Overfitting dalam Machine Learning
Halo, Sobat Data!
Selamat datang di #KuliahData! Di sesi ini, Sobat Data akan diajak untuk mengenali berbagai konsep dalam dunia Data Science yang akan membantu memahami bagaimana teknologi kecerdasan buatan bekerja di balik layar. Mulai dari pemrograman, analisis data, hingga konsep pembelajaran mesin yang menjadi fondasi utama dalam pengembangan sistem cerdas.
Pada sesi kali ini, Sobat Data akan dikenalkan dengan konsep penting dalam Machine Learning, yaitu Underfitting dan Overfitting. Kedua konsep ini sangat sering muncul ketika Sobat Data mulai membangun model prediksi. Penasaran kenapa model Machine Learning bisa salah dalam mempelajari data? Yuk kita bahas bersama, Sobat Data!
Sobat Data, pernah nggak sih membayangkan bagaimana sebuah model Machine Learning bisa belajar dari data? Dalam proses pembelajaran mesin, model akan mencoba menemukan pola dari data yang tersedia agar dapat memprediksi data baru dengan lebih akurat. Namun, proses belajar ini tidak selalu berjalan sempurna. Terkadang model bisa terlalu sederhana atau terlalu kompleks dalam memahami pola data. Di sinilah konsep Underfitting dan Overfitting menjadi sangat penting.
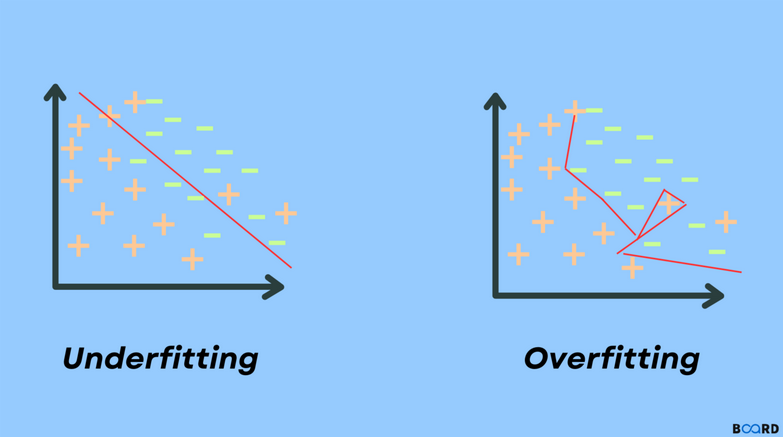
Underfitting terjadi ketika model Machine Learning terlalu sederhana untuk menangkap pola penting dalam data. Model dengan kondisi underfitting biasanya memiliki performa yang kurang baik, baik pada data training maupun data testing, karena model belum mampu memahami hubungan antar variabel dengan optimal. Underfitting bisa terjadi jika model memiliki kompleksitas yang terlalu rendah atau fitur yang digunakan belum cukup merepresentasikan data. Dalam analogi sederhana, underfitting bisa diibaratkan seperti seseorang yang baru belajar dan belum memahami materi dengan baik.
Sebaliknya, Overfitting terjadi ketika model Machine Learning terlalu “menghafal” data pelatihan. Model tidak hanya mempelajari pola penting, tetapi juga mempelajari noise atau pola yang sebenarnya tidak relevan. Akibatnya, model memiliki performa yang sangat baik pada data training, tetapi menurun ketika digunakan pada data baru. Overfitting sering terjadi pada model yang terlalu kompleks atau ketika jumlah data pelatihan tidak cukup banyak untuk melatih model secara optimal.
Dalam pengembangan Machine Learning, tujuan utama adalah menemukan keseimbangan antara Underfitting dan Overfitting. Sobat Data perlu membangun model yang mampu menangkap pola penting tanpa menghafal detail yang tidak relevan. Konsep ini berkaitan dengan keseimbangan antara bias dan variansi dalam model pembelajaran mesin. Bias yang terlalu tinggi dapat menyebabkan underfitting, sedangkan variansi yang terlalu tinggi dapat menyebabkan overfitting.
Untuk mengatasi Overfitting, terdapat beberapa teknik yang sering digunakan dalam praktik Machine Learning, seperti regularisasi, penambahan data pelatihan, dan evaluasi model menggunakan data testing yang terpisah. Teknik-teknik ini membantu memastikan model mampu bekerja dengan baik pada data yang belum pernah dilihat sebelumnya.
Konsep Underfitting dan Overfitting sangat penting dalam pengembangan sistem berbasis data, terutama dalam tugas prediksi dan klasifikasi. Memahami kedua konsep ini akan membantu Sobat Data dalam membangun model yang lebih stabil, akurat, dan dapat diandalkan dalam menyelesaikan berbagai permasalahan dunia nyata.
Demikian pembahasan tentang Underfitting dan Overfitting dalam Machine Learning. Konsep ini menjadi dasar penting dalam perjalanan Sobat Data untuk memahami bagaimana model kecerdasan buatan belajar dari data. Jadi, terus semangat belajar dan jangan berhenti mengeksplorasi dunia Data Science! 🚀📊
Sampai jumpa di #KuliahData selanjutnya! Teruslah termotivasi dan jangan berhenti mengejar mimpi-mimpimu! 🚀📊
Yuk segera daftarkan diri kamu di Data Science Telkom University Surabaya dan wujudkan impianmu!
Playing with Data, Winning the Era.
More info :
-Website : https://bds-sby.telkomuniversity.ac.id/
-Instagram : https://www.instagram.com/ds.telkomsurabaya/